



十年筑基谋跨越 智启新程向未来——国家生物信息中心大数据资源体系建设十年发展纪实
深耕不辍,厚积薄发。从跟跑并跑到引领跨越,国家生物信息中心大数据资源体系建设伴随中国生命科学的高质量发展,已走过十年不凡历程。值此十周年之际,中心正站在从“信息中心”迈向“智能中心”的关键节点,回望使命演进之路,擘画未来发展蓝图。
破局阶段:从零起步,构筑国家级数据基石
2016年初,中国科学院北京基因组研究所组建生命与健康大数据中心(BIGD),打破传统科研模式,打造国内首个体系化的组学数据公共平台。此前,我国基因组数据长期递交至国际核酸序列数据库联盟(INSDC)。为向世界提供生命科学领域数据管理与共享的中国方案,BIGD于2016年上线国内首个组学原始数据归档库(GSA),实现了组学数据国内汇交零的突破。随后,中心陆续推出基因组数据库(GWH)、基因组变异库(GVM)、基因表达数据库(GEN)等一系列核心数据库,初步形成覆盖多类型组学数据的资源体系。2019年6月,科技部、财政部联合发布国家科技资源共享服务平台名单,国家基因组科学数据中心(NGDC)正式获批,由BIGD团队承担建设。此举标志着我国生物数据管理拥有国家级平台,为后续发展奠定了坚实的体制基础。
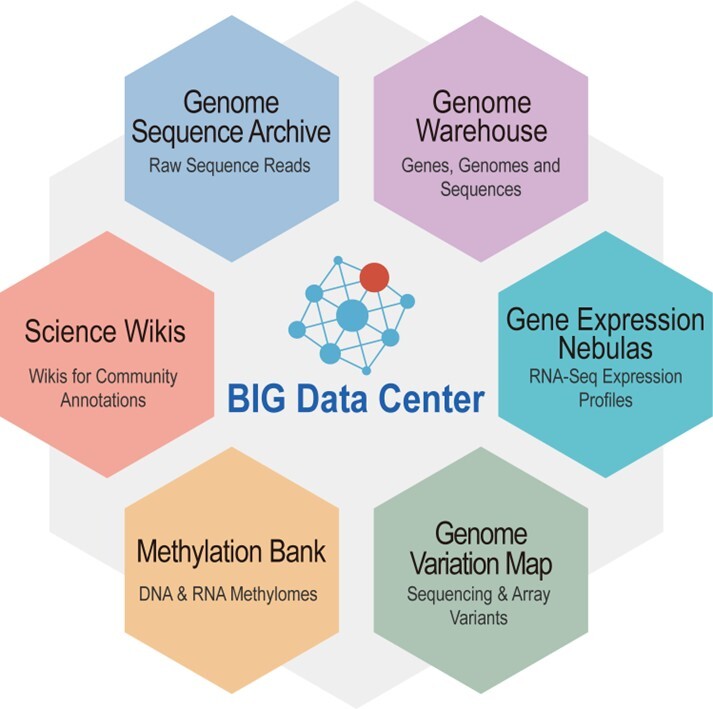
BIGD数据资源(2017)
跨越阶段:并跑国际,彰显国家战略科技力量
2019年11月,中央编办批复中国科学院北京基因组研究所加挂国家生物信息中心(CNCB)牌子。2024年4月,中国科学院党组批复由北京基因组研究所整建制转型,承担国家生物信息中心建设运行任务。CNCB的职能涵盖国家生物信息大数据的统一汇交、集中存储与安全管理,以及前沿交叉研究与转化应用。作为核心功能单元,NGDC的使命从数据存储拓展为数据驱动型国家战略科技力量,致力于将海量数据转化为高价值信息,支撑生命健康产业创新发展。至2026年2月,中心数据资源规模持续跃升:数据库从成立初的15个扩展至110余个,涵盖9大数据类型,累计数据量超过100PB,支撑国家重点研发计划、国家自然科学基金、中国科学院战略先导专项等四万余个科研项目的数据工作。国际影响力实现跨越:GSA成为国内首个获Springer Nature、Elsevier、Wiley、Taylor & Francis、Cell等全球主流学术出版集团认可的数据递交平台,并入选全球核心生物数据资源(GCBR);中心实现对美国国家生物技术信息中心(NCBI)GenBank和SRA数据库数据资源的全面整合与同步更新;连续九年在国际生物数据库权威期刊《核酸研究》的年度数据库专刊中,与美国NCBI、欧洲EBI并列为全球主要生物数据中心,实现从跟跑到并跑。建设成果入选国家“十三五”科技创新成就展和“奋进新时代”主题成就展。
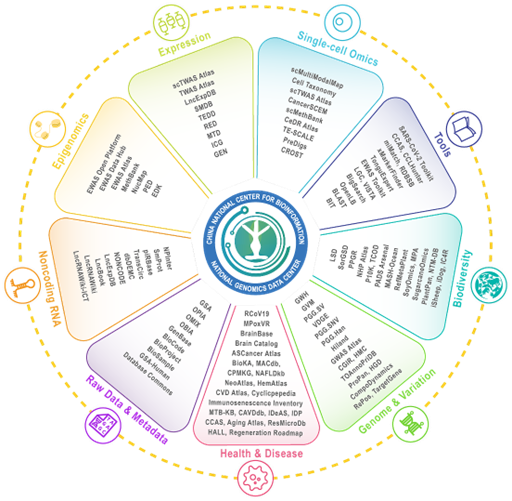
NGDC生物大数据一体化资源体系(2026)
跃升阶段:智领未来,从信息中心迈向智能中心
当前,人工智能深度融入生命科学,对数据标准化、可计算性提出全新要求。面向这一趋势,NGDC正有力支撑CNCB从信息中心向智能中心的跃升,核心是重构数据价值。中心以数据治理智能化、标准全息化、语料资源化为方向,打造生命科学领域的AI语料资源中枢,实现从人工清洗到AI自动标注的转变,建立生物数据全息标准体系,为基因组、影像、表型等多模态数据的深度融合提供通用语言,打通AI赋能生命科学的“最后一公里”。工作重心从数据的集中存储管理,转向数据的深度加工与价值释放,为AI for Science研究提供高质量、大规模的“数据燃料”,赋能精准医学、新药研发、生物育种等未来产业,助力实现高水平科技自立自强。
十年磨一剑,今朝启新程。从BIGD的拓荒启航,到NGDC的跨越发展,再到CNCB智能中心蓝图绘就,变化的是一代代科研人攻坚克难的技术前沿,不变的是服务国家战略的初心使命。
站在新的历史起点,NGDC将继续以数据为基、以智能为翼,在生命科学高质量发展的新征程上,持续贡献中国数据智慧、彰显中国数据力量。


