



国家生物信息中心多组学数据资源体系持续拓展和更新
国家生物信息中心(CNCB)在建立生物信息大数据汇交存储、安全管理、开放共享与整合挖掘中持续发力,为人工智能(AI)重塑生命科学研究范式筑牢数据基座。近日,国家生物信息中心全面总结了2025年度国家基因组科学数据中心(NGDC)在各类数据资源、知识信息和算法工具开发上的进展,以“Database Resources of the National Genomics Data Center, China National Center for Bioinformation in 2026”为题,在学术期刊Nucleic Acids Research上在线发表。
2025年,CNCB-NGDC与2家共建单位及70余家合作单位密切协同,依托相关机构新设立5家分中心,持续加强多组学数据整合与知识融合,不断升级完善核心数据库体系(GSA、GenBase、GWH、GVM、GEN、MethBank、LncRNA等),并开发了一系列新的数据库,涵盖基因组与变异(Hiland Resource、TOAnnoPriDB)、表达(TEDD)、单细胞组学(PreDigs、scMultiModalMap、TE-SCALE)、影像组学(TonguExpert)、健康与疾病(CAVDdb、IDP、MTB-KB、ResMicroDb)、生物多样性与生物合成(SugarcaneOmics),以及分析工具(Dingent、miMatch、OmniExtract、RDBSB、xMarkerFinder),进一步完善了覆盖基础组学、人类遗传、重要战略生物、病毒数据以及生物信息在线分析工具在内的多组学资源体系。上述资源与服务均可通过https://ngdc.cncb.ac.cn免费获取和使用。
目前,CNCB-NGDC已经建立起集“数据-信息-知识”于一体的生物大数据多维资源体系,118个专业数据库系统汇聚覆盖元信息、基因组、变异组、转录组、表观组、影像组及多模态等多组学高质量数据,有力支撑国家基因组科学数据的汇交共享、安全管理与深度挖掘利用。依托该体系面向“存储–整合–应用”提供多层次服务,收录归档数据92PB,累计服务用户超过5,822万人次,支撑5,051篇论文发表于651种中外期刊,平台总访问量超过7.15亿次,显著提升了我国生物大数据的配置效率和创新效益。
CNCB-NGDC的建设得到科技部、财政部、中国科学院以及国家自然科学基金委等的资助。
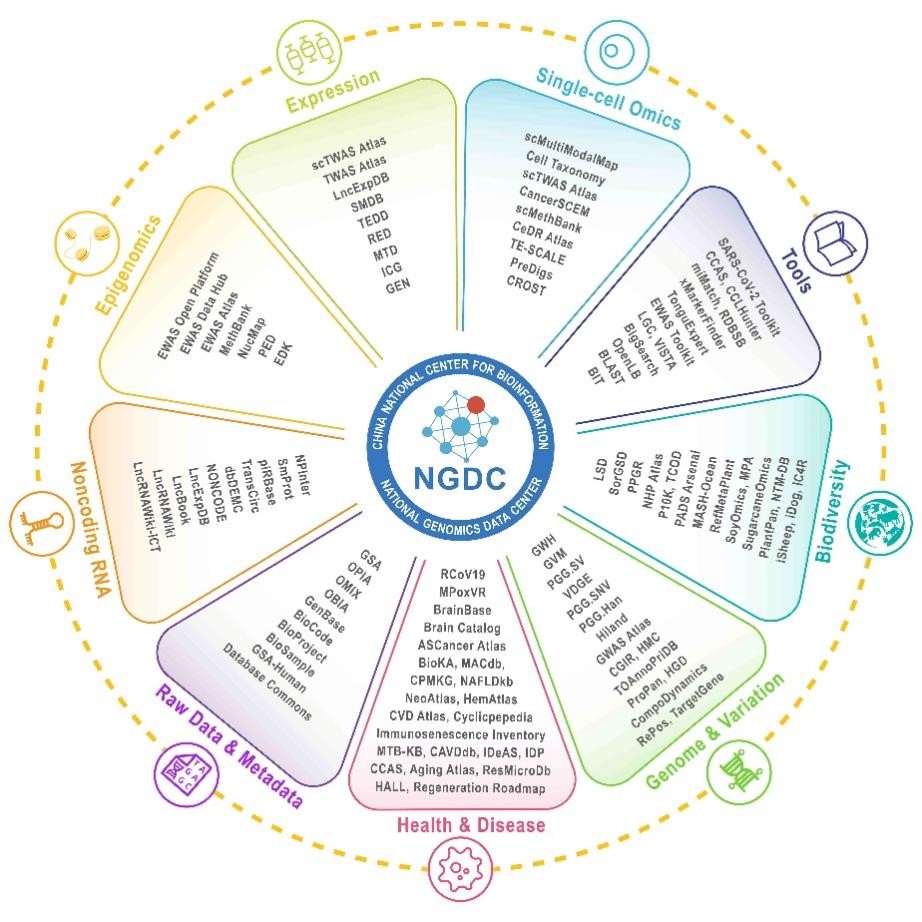
CNCB-NGDC多组学数据资源体系


