



北京基因组所(国家生物信息中心)合作构建中国汉族人二倍体端粒到端粒高精度基因组参考序列
自30年前“人类基因组计划”(HGP)启动以来,完整和准确的参考基因组一直是生物医学研究领域致力追求的目标。2022年4月,Science期刊发表了首个人类端粒到端粒(T2T)完整基因组——T2T-CHM13,填补了GRCh38版本中剩余的8%人类基因组序列空白,成为有史以来第一个高质量的单倍体人类基因组。近年来研究证实人种之间存在显著的基因组序列差异,而参考基因组与待测样本之间的差异会严重影响基因组分析中变异识别的准确性,以及后续精准医学大数据分析的可靠性。华人作为世界上人口数量最多的人群之一,一直缺乏高质量完整参考基因组序列,在精准医学研究和临床基因组诊断中,只能使用美国NIH主持构建的高加索人基因组作为参考序列,难以满足中国人基因组分析的精度要求和我国精准医学发展需求。
近日,中国科学院北京基因组研究所(国家生物信息中心)康禹研究员与北京大学人民医院高占成教授合作构建代表汉族中国人基因组特征的人类T2T二倍体参考基因组——“唐尧”基因组(T2T-YAO),该成果于日前正式在Genomics, Proteomics & Bioinformatics 刊发。T2T-YAO的单倍型拼接质量达到Q74.69,即1个错误/29.4 Mb(Mb,百万碱基),甚至超过了T2T-CHM13 v1.1的Q73.94(1个错误/24.5 Mb),成为目前国际上已经发表的拼接质量值最高的人类基因组之一。

期刊封面
T2T-YAO的DNA样本来自山西临汾洪桐县一名世代居住的汉族健康男青年外周血,因采样地临近4000年前的尧帝的都城遗址,故命名为“唐尧”。祖源分析显示,“唐尧”基因组的祖源标记(SNP)基本为东亚人群。其Y染色体单倍群被鉴定为O-F2137(O2a2b1a1a1a2a),是中国主要Y单倍群O-M122的主要后代群之一,与祖源分析结果一致。此外,洪桐地区也是明初洪武大移民的起点。这场持续了近半个世纪(公元1370 — 1417年)的大规模移民,其后代遍布中国,乃至东南亚各地。因此,T2T-YAO可以更好地代表中国汉族人群的基因组特征。
使用国际通用的Merqury算法和 T2T-YAO拼接用的原始Hiseq和HiFi 测序数据可以精确评估T2T-YAO拼接的完整性、错误率和父母单倍型之间的交换错误。结果显示T2T-YAO的母本与父本的完整性分别为99.65%和99.59%,质量值分别达到了Q70.49和Q72.28,母本与父本的交换错误分别为0.019%和0.0113%,是目前高拼接质量的人类二倍体基因组。进一步选取父母本中质量较高的22条常染色体以及X、Y染色体组成一套完整的人单倍型参考基因组,其质量达到了Q74.69,超过T2T-CHM13(Q73.94)。此外,利用数字PCR技术证实T2T-YAO中最复杂的rDNA区重复单元数量、重要多拷贝基因的拷贝数、以及 X染色体中卫星区域都得到正确组装。
综上,“唐尧”基因组(T2T-YAO),是目前完整性和准确性最高的人类二倍体参考基因组,包含了难度最大的rDNA区所在的近端着丝粒染色体短臂和Y染色体。T2T-YAO的完整序列将深化我们对人类基因组学,尤其是中国汉族人的基因组特征的理解,并为未来的医学研究和临床实践提供重要的参考基线和研究基础。
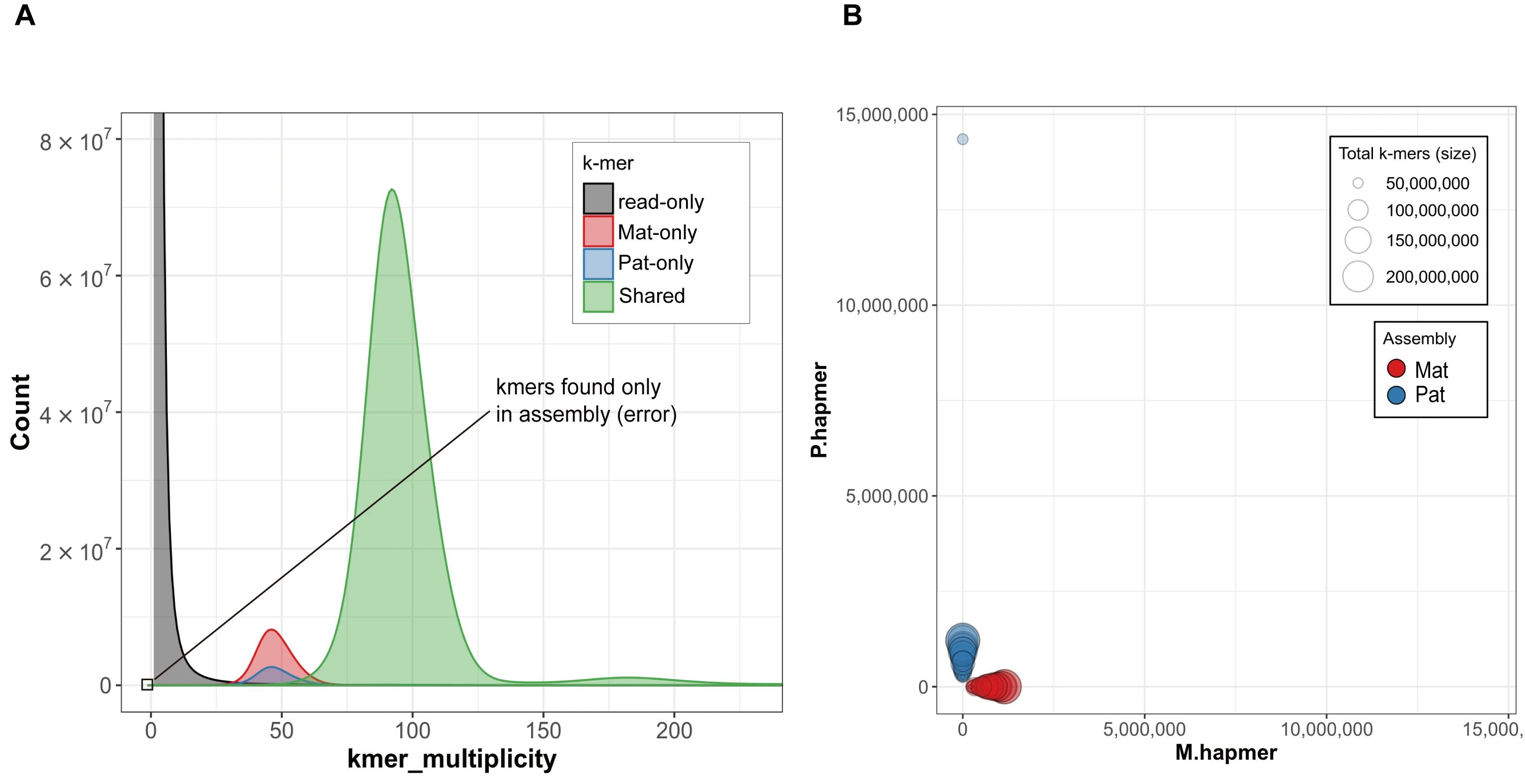
T2T-YAO组装的完整性和质量评估
中国科学院北京基因组研究所(国家生物信息中心)楚亚男、北京大学人民医院何玉坤、李冉、临汾市中心医院郭淑明、厦门大学医学院郑雅丽、未来组生物科技有限公司胡江为该文共同第一作者,中国科学院北京基因组研究所(国家生物信息中心)康禹研究员和北京大学人民医院高占成教授为该文共同通讯作者。


